
Objectifs de certification
CCNA 200-301
2.5 Décrire la nécessité et les operations de base de Rapid PVST+ Spanning Tree Protocol
- 2.5.a Root port, root bridge (primary/secondary), et les autres noms de port
- 2.5.b Port states (forwarding/blocking)
- 2.5.c Avantages PortFast
2.4 Configurer et vérifier (Layer 2/Layer 3) EtherChannel (LACP)
3.5 Décrire le but des protocoles de redondance du premier saut (first hop redundancy protocol)
2.1 Configurer et vérifier les VLANs (normal range) couvrant plusieurs switches
- 2.1.a Access ports (data et voice)
- 2.1.b Default VLAN
- 2.1.c Connectivity
2.2 Configurer et vérifier la connectivité interswitch
- 2.2.a Trunk ports
- 2.2.b 802.1Q
- 2.2.c Native VLAN
Solutions de disponibilité dans le LAN
Dans ce chapitre introductif de conception des réseaux locaux, on identifiera les différents modèles de conception dans lesquels interviennent les solutions de disponibilité dans le réseau local (LAN) telles que Etherchannel, Rapid Spanning-Tree, HSRP et le routage IP. Le propos développé ici invite au déploiement de ces topologies dans des exercices de laboratoires. On ne manquera enfin de rappeler le principe de la sécurité par conception.
1. Solutions de disponibilité dans le LAN
Les solutions de redondance dans le LAN qui contribuent à la haute disponibilité1 dans les réseaux LAN sont les suivantes : Etherchannel, Rapid Spanning Tree, HSRP ou VRRP et les protocoles de routage.
| Couche | Protocole/Solutions | Délais de reprise |
|---|---|---|
| L1 | Etherchannel | Plus ou moins 1 seconde pour rediriger le trafic sur un lien alternatif |
| L2 | Rapid Spanning Tree | Quelques secondes |
| L3 | First Hop Redundancy Protocols comme HSRP, VRRP, GLBP | 10 secondes par défaut (Cisco) mais le constructeur conseille 1s hello time, 3s Hold Time |
| L3 | Protocoles de routage | En dessous de la seconde avec OSPF ou EIGRP |
2. Redondance de couche 1
Etherchannel peut cumuler plusieurs liaisons physiques (L1) en terme de fiabilité et de charge. Chaque groupe Etherchannel est vu comme une interface logique pour le commutateur. Du point de vue de Spanning-Tree, ce sont les interfaces “Port-Channel” qui seront prisent en compte dans le calcul d’une topologie sans boucle. Dans ce cadre, Etherchannel contribue à simplifier les topologies Spanning-Tree.
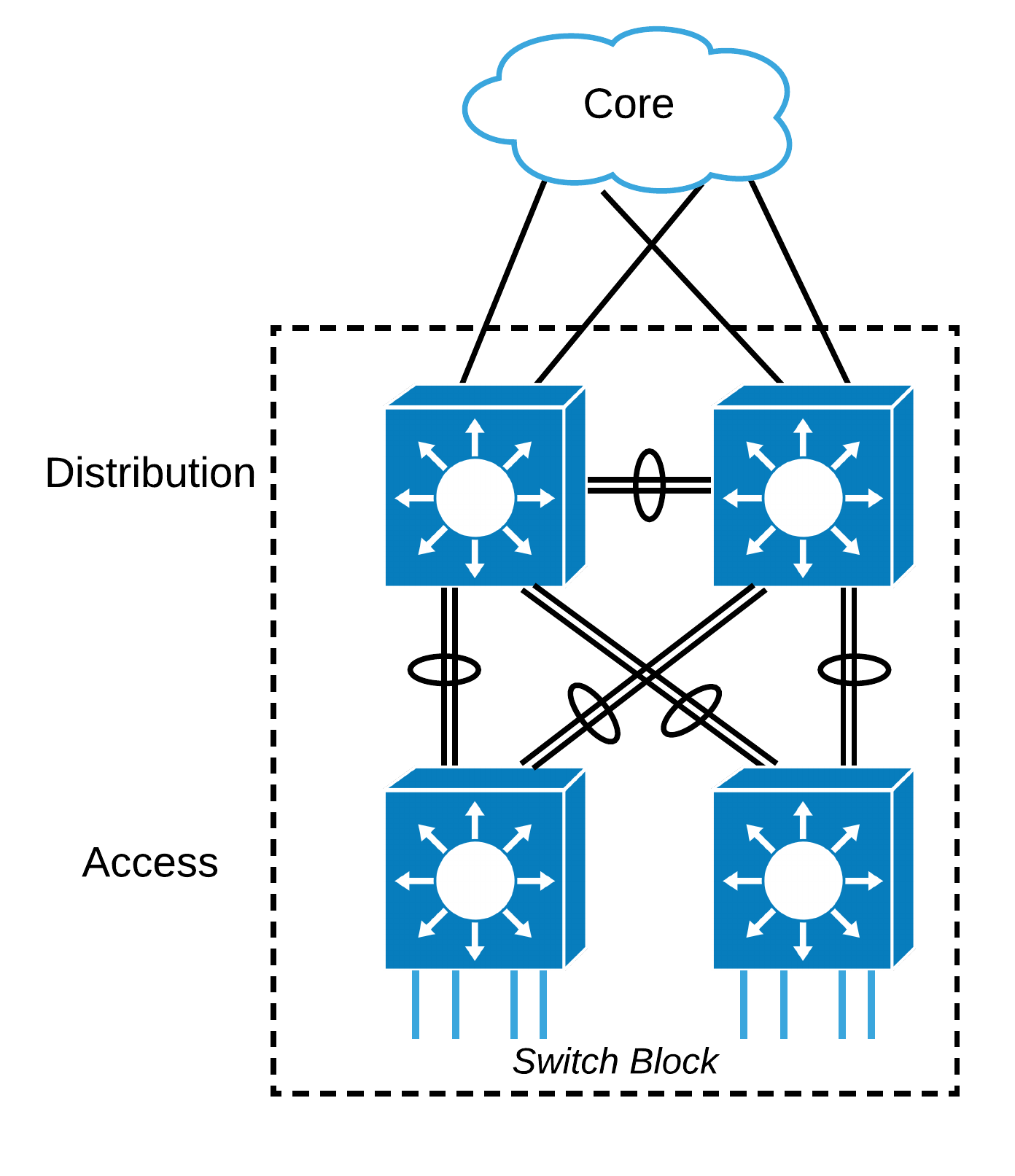
3. Redondance de couche 2
Spanning-Tree est activé par défaut sur les commutateurs Cisco. Il se déploie habituellement pour assurer la redondance entre la couche Access et la couche Distribution. Le routage IP — soit la couche 3 (L3) — intervient entre la couche Distribution et la couche Core. On activera de préférence des protocoles comme Rapid STP ou MST dont les délais de reprise pourraient en satisfaire certains.
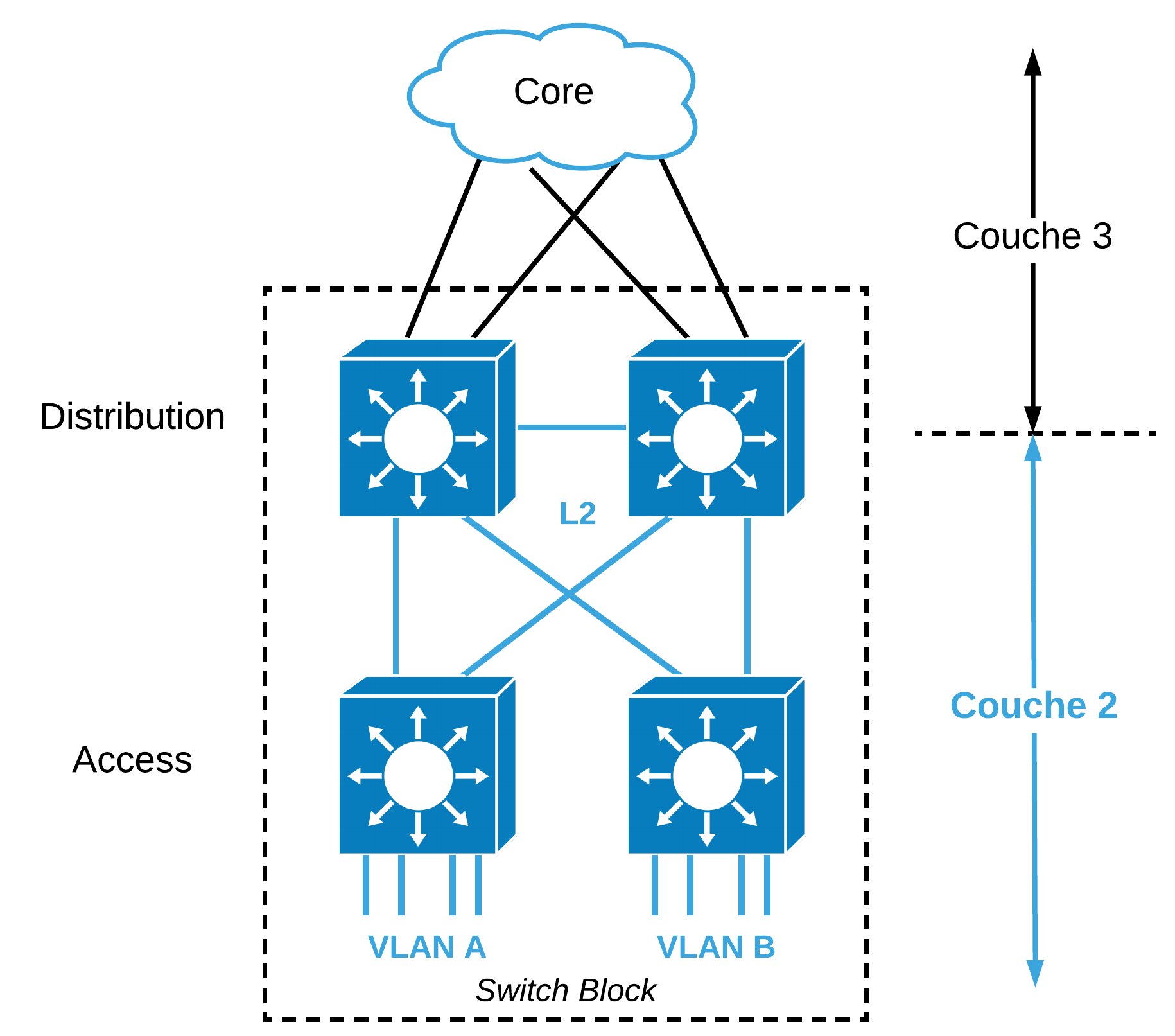
Ici, les VLANs peuvent s’étaler sur les commutateurs Access et le réseau est physiquement “bouclé”. Dans une situation idéale, une seule liaison est activée entre la couche Access et la couche Distribution. Grâce à Spanning-Tree avec les deux commutateurs configurés “Root Primary” pour certains VLANs et “Root Secondary” pour d’autres, l’un peut reprendre le rôle “root” pour l’autre et on peut distribuer la charge de plusieurs VLANs sur des liaisons alternatives. Toutefois, si une connexion vers la couche Distribution tombe, le trafic du VLAN impliqué passera par le “Trunk” alternatif cumulant le trafic de tous les VLANs et passera par un commutateur intermédiaire pour joindre son ancien commutateur “root”. On imagine que la rapidité de Spanning-Tree est un enjeu dans ce type de topologie.
Dans la figure suivante, le trafic du VLAN 10 passe de manière optimale par DS1. En effet, DS1 est “root primary” pour le VLAN 10. L’interface de AS1 qui pointe sur DS2 est nécessairement “non-designated” et en état STP “Blocking”. Toutefois, si la connexion entre AS1 et DS1 venait à tomber, le trafic du VLAN 10 vers DS1 passerait de bout en bout par le “trunk” entre AS1 et DS2 et puis par le “trunk” entre DS2 et DS1.
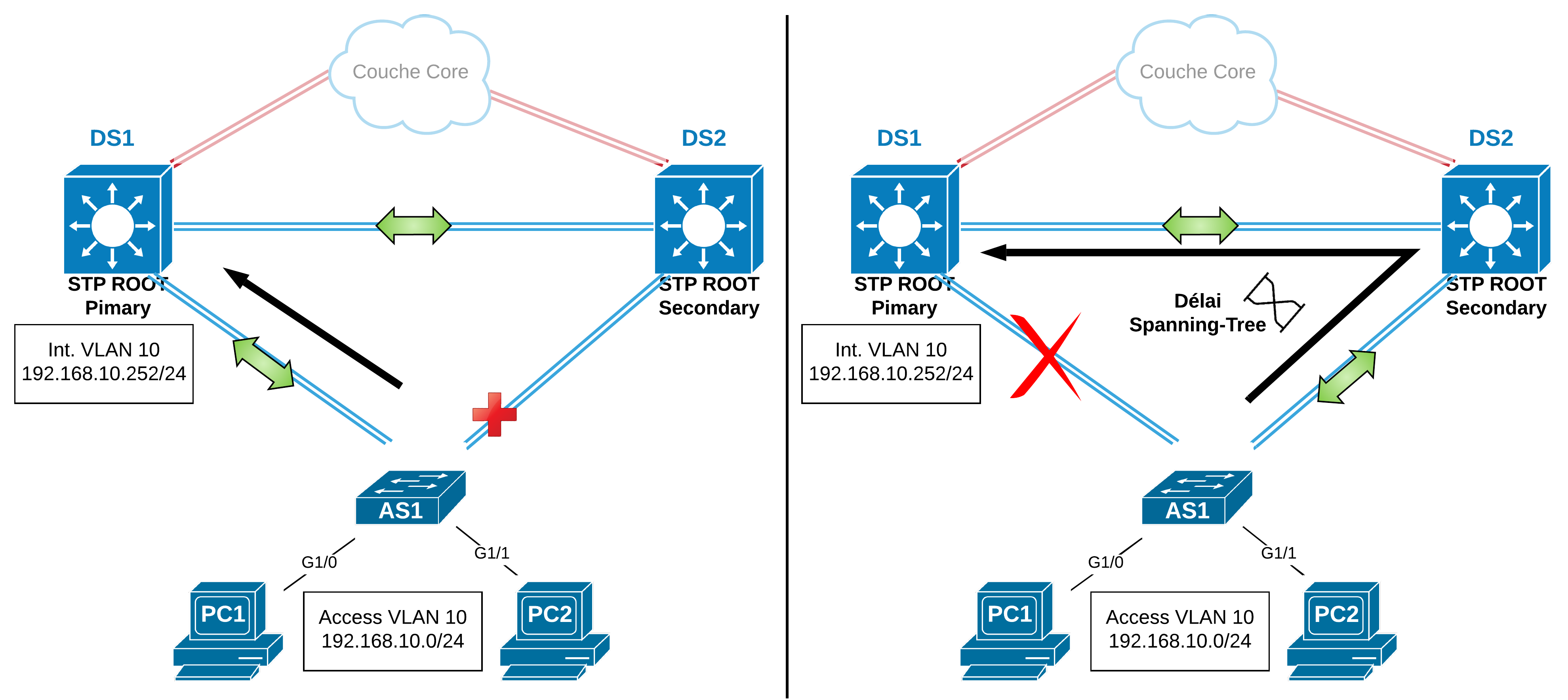
Les VLANs “éparpillés” continuent à communiquer entre eux mais leur passerelle reste un point unique de rupture. Dans ce cadre, un protocole de redondance du premier saut (First Hop redundancy Protocols, FHRP) comme HSRP, VRRP ou GLBP assure la redondance de la passerelle et le nouveau commutateur root (secondaire) peut prendre en charge le routage des paquets.

4. Redondance de couche 3
Si l’on imagine que l’un peut devenir passerelle pour l’autre de manière cohérente grâce à HSRP, on disposera d’une mesure de protection en cas de passerelle totalement indisponible. S’il ne s’agit jamais que d’une rupture entre le commutateur Distribution et le commutateur Access, c’est Spanning-Tree qui entrera jeu de manière relativement rapide mais toujours moins que le routage ou HSRP. La passerelle sera toujours joignable mais le trafic passera par un chemin sous-optimal dépendant de Rapid Spanning-Tree et de son délai (jusqu’à 6 secondes). Dans ce type d’architecture courante, il est nécessaire que les commutateurs Root et la passerelle par défaut (HSRP ou VRRP) correspondent.
Une autre solution de conception consiste à diminuer l’étendue de la couche 2, soit de Spanning-Tree dans la couche distribution, une “topologie sans boucle de couche 2”. Spanning-Tree est toujours présent par mesure de précaution et éventuellement pour répondre à une bonne pratique. On sera attentif au fait que ce type d’architecture exige que les IDs VLANs ne s’étendent pas sur plusieurs commutateurs de couche Access, ces IDs devant être alors uniques sur chacun d’eux. La gestion des VLANs devient alors locale aux commutateurs d’accès.
Dans la figure suivante, chaque VLAN est strictement déployé sur un commutateur Access. Un lien L3 entre les commutateurs Distribution coupe naturellement la boucle Spanning-Tree L2 selon un “modèle HSRP” (Layer 2 Loop-Free Topology). Les routeurs HSRP redondants dans la couche Distribution se voient à travers la couche Access.

Aussi, pourquoi maintenir des liaisons L2 entre la couche Access et Distribution si les VLANs se limitent localement sur les commutateurs d’accès et ne s’éparpillent pas ? On peut alors considérer du routage IP statique par défaut vers les commutateurs de couche Distribution à partir des commutateurs Access. Par défaut Spanning-Tree sera maintenu, mais il ne disposera plus de rôle critique dans une infrastructure entièrement routée dans le réseau local.
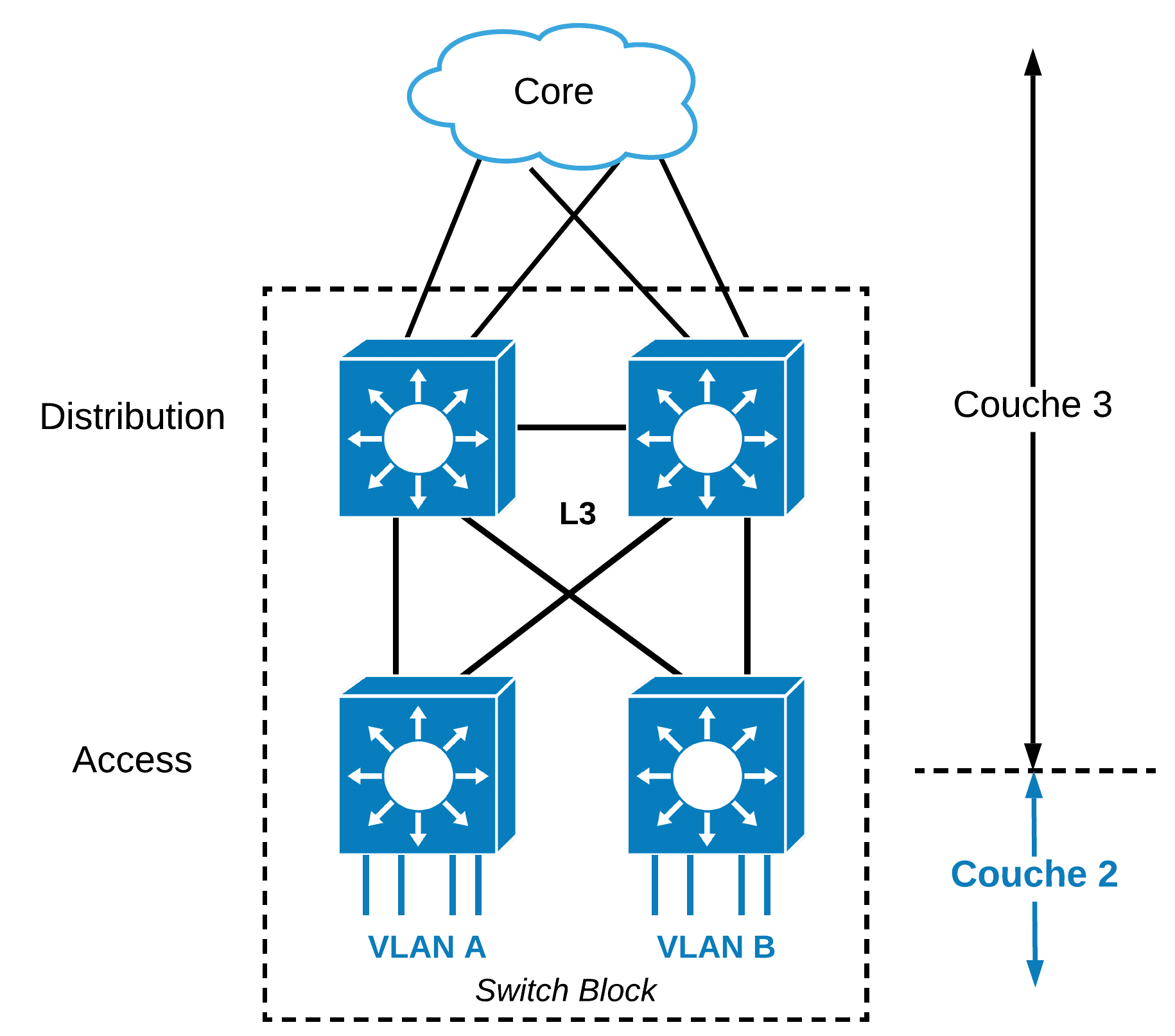
Dans ce type de déploiement, la couche Access assure les fonctions de routage IP.
5. Redondance des liaisons L3 (Routage)
Des interfaces routées redondante, c’est-à-dire des liaisons redondantes auxquelles on a attribué des adresses IP comme les interfaces des routeurs ou encore des interfaces no switchport des commutateurs pourraient aider à atteindre un niveau de disponibilité suppérieur.
Dès qu’une interface IP connait des problèmes L1/L2 comme une interruption physique, le routeur ou le commutateur retirera immédiatement l’interface problématique de sa table de routage comme interface de sortie. Toutes les routes associées à cette interface seront supprimées, ce qui aura pour effet de répartir le trafic sur les meilleures liaisons alternatives. Si des routes statiques étaient associées à cette interface, elles seront supprimées (voir routes flottantes) ; si des routes apprises par un protocole de routage étaient associées à cette interface, elles disparaîteront également de la table de routage mais cela ne signifie pas nécessairement que le chemin alors choisi sera optimal.
Faudra-t-il encore que la méthode de routage puisse s’adapter de manière efficace afin de créer une topologie de transfert sans boucle dans les plus brefs délais, réduisant ce que l’on appelle le délai de convergence. Plus la convergence est lente, plus le taux de disponibilté chutera. Seuls OSPF ou EIGRP peuvent répondre à ces deux critères anti-bouclage et rapidité. RIP, quel que soit sa version, sera à la fois particulièrement sensible aux boucles de routage et lent à “converger”.
Aussi, le routage dynamique et ses protocoles comme OSPF ou EIGRP sur matériel Cisco sont capables de répartir la charge du trafic vers une même destination sur plusieurs liaisons équivalentes de manière efficace. EIGRP est même capable d’utiliser des liaisons plus coûteuses à condition que celles-ci soient réputées sans boucle. Cette technique appelée dans le jargon “Unequal Load Balancing” permettrait de répartir la charge de trafic proportionnellement au coût des meilleures laisons alors que celle-ci n’aurait jamais été utilisée avec une répartion de charge égale (la seule disponible en OSPF). Cette fonctionnalité EIGRP remarquable, associée concept de variance, demande réflexion avant déploiement car son usage pourrait avoir des effets secondaires (“effets de bord”), indésirables, coûteux ou inattendus. En cas de doute, le support technique de Cisco Systems est à votre écoute.
6. La sécurité par conception
Enfin, la mise en oeuvre de tous ces protocoles L1/L2/L3 exigerait que l’on se pose une question préalable, bien réelle : si des éléments extérieurs venaient à se connecter à l’infrastructure, est-ce qu’ils pourraient discuter librement avec ces protocoles CDP, VTP, 802.1q, DTP, HSRP, VRRP, EIGRP, OSPF ? Si cela était le cas, ces éléments extérieurs pourraient endommager l’infrastructure, redigirer du trafic sur de mauvais chemins ou encore s’immiscer dans les communications de manière involaire ou malveillante.
Nombreux sont les cas de rupture de service connus suite à la connexion d’un périphérique externe (pirate ou non) au réseau qui devient STP Root détruisant ainsi la topologie initiale. Des périphériques de communication domestiques ou venant d’opérateurs sont parfaitement capables de fonctionner en Spanning-Tree par exemple. Qui des professionels des réseaux n’a jamais connu l’expérience d’une tempête de Broadcast ? Les commutateurs pirates et les périphériques non autorisés sont légions dans certains réseaux d’entreprise, surtout s’ils sont hétérogènes.
Dans leur plus simple configuration, telle que certains diplômes CCNA les présentent, ces protocoles d’infrastructure et de contrôle sont particulièrement crédules. Au moment de la conception, et il n’est probablement jamais assez tôt comme trop tard pour y penser, on se souciera des interactions autorisées sur le plan du contrôle et de la gestion : authentification des message, filtrage basé sur la provenance ou la nature des messages, etc. Cette démarche demande simplement d’intégrer l’aspect sécurité dans la conception.
Il est d’ailleurs trivial de démontrer les vulnérabilités des configurations faibles en sécurité, des configurations qui laissent subsister des paramètres par défaut ou des environnements qui n’ont pas été audités. Les contre-mesures des fabricants comme Cisco sont à diposition des utilisateurs, bien souvent disponibles sans frais supplémentaires. Mais leur mise en place demandent un investissement en matière de compétences techniques et culturelles, et surtout en temps.
Alors que les commutateurs ont pour fonction principale de transférer le plus rapidement possible le trafic L2 au sein du réseau, ceux-ci ont acquis au fil du temps des fonctions L3 de routage et de services IP, et puis des fonctions de sécurité et de vérification du trafic de plus en plus avancées. Si les fonctions de bas niveau sont assurées par des puces dédiées comme des ASICs, les commutateurs d’entreprise deviennent de puissants ordinateurs du réseau, notamment dans les gammes de périphériques Cisco.
Enfin, la mise en place d’une solution de surveillance qui journalise les événements et qui est capable de les rapporter afin de remonter des alertes, de les analyser pour vérifier l’état de santé de l’infrastructure entière, ou encore pour remédier automatiquement ou non aux problèmes constatés, etc. est partie intégrante d’une conception sécurisée du réseau. Mais de nouveau, ce type de projet aussi avancé demande un certain investissement en compétences et en temps.
De nouveaux modèles d’infrastructures comme SDN ou des solutions basées sur les technologies en nuage ou qui s’en inspirent facilitent réellement ce type de gestion. Il y a toujours de la place pour des outils de surveillance comme Nagios ou Zabbix par exemple, mais de nouveau outils dotés de capacités de collecte, d’analyse, de présentation et de réaction aux événements du réseau ont fait récemment leur apparition. Ces derniers s’intègrent aux solutions traditionnelles de surveillance qui utilisent Syslog et SNMP mais ajoutent des nouvelles méthodes de collecte, de stockage, de traitement et de présentation de données qui correspondent aux attentes du marché. On imagine alors les capacités nécessaires et la maintenance en soi de telles solutions. Heureusement, l’Open Source démocratise des solutions qu’à une époque seules les entreprises les plus fortunées pouvaient se payer. On citera par exemple projet netdata.io.
Le jargon disponibilité, haute disponibilité (HA), Tolérance aux pannes (FT), redondance, robutesse, résilience, taux de disponibilité ou d’indisponibilté, point unique de rupture (single point of failure), isolation des pannes, plan de reprise d’activité, plan de continuité d’activité est un sujet en soi. ↩
